Индекс - «бинарное дерево»
Любой бинарный алгоритм поиска в упорядоченном файле БД можно представить с помощью соответствующего бинарного дерева [17]. Это бинарное дерево можно реализовать в виде самостоятельного файла (или индекса). При этом операции поиска будут освобождены от необходимости каждый раз вычислять адреса записей (они будут сформированы один раз при начальной загрузке файла БД и при последующих добавлениях в файл новых записей).
На рис. 3.8 представлено бинарное дерево, построенное для файла из 15 записей [17]. Запись бинарного дерева состоит из поля ключа записи и двух полей указателей. Один указатель для левого поддерева, другой – для правого поддерева. Листовые записи бинарного дерева содержат указатели на блоки файла основных записей (файла данных). Для уменьшения количества операций обмена с внешней памятью при выполнении поиска соседние записи в бинарном дереве объединяются в блоки. На слайде объединяемые в один блок записи бинарного дерева очерчены штриховой линией.
Записи бинарного дерева обычно меньше по объему памяти записей основного файла
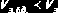
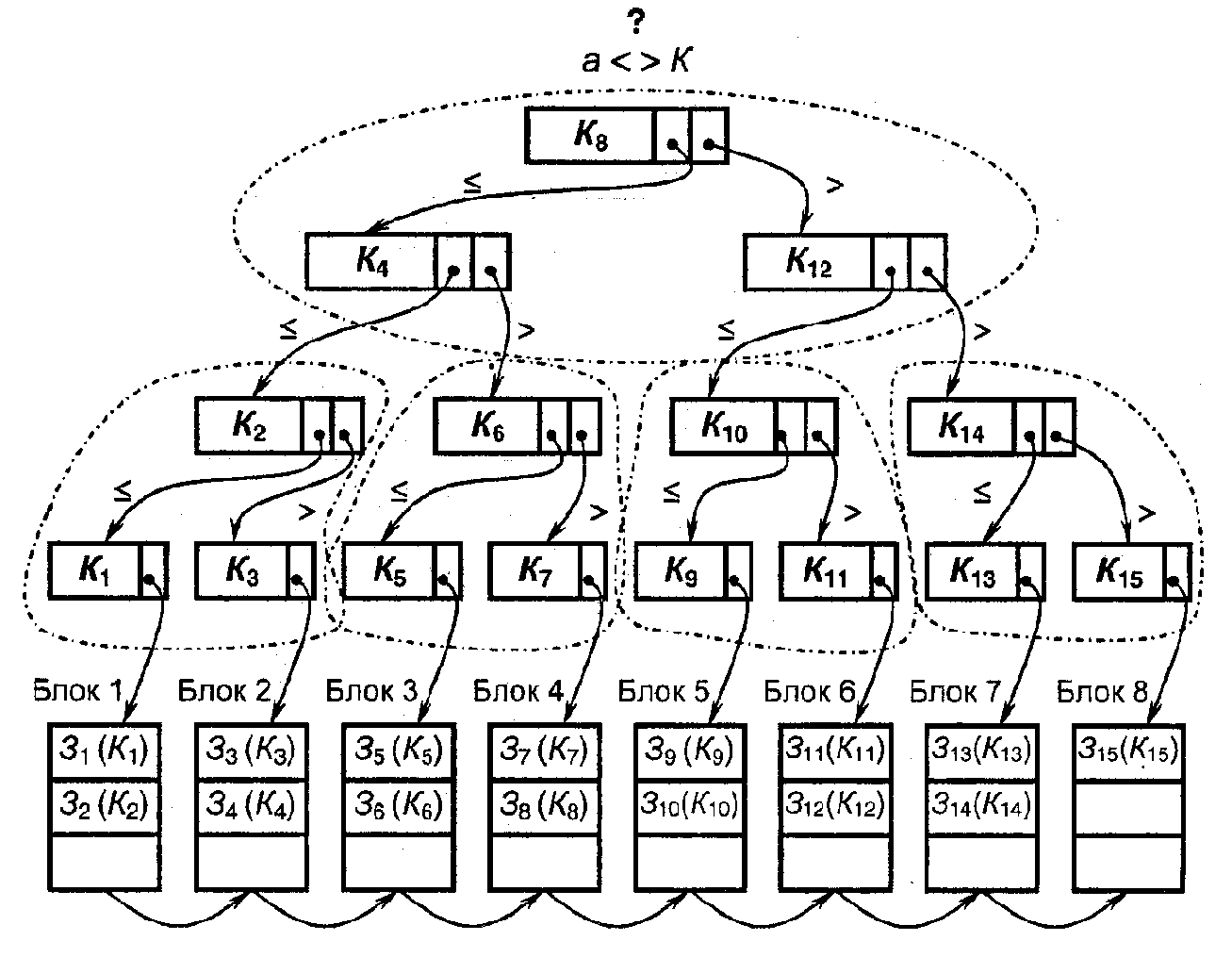
Рис. 3.8. Пример бинарного дерева
Реализация бинарного дерева позволяет сократить время поиска данных по сравнению с бинарным поиском, однако возрастает требуемый объем внешней памяти [17].