Последовательное распределение памяти
Последовательное распределение – простой и естественный способ хранения линейного списка. В этом случае узлы списка размещаются в последовательных элементах памяти (рис.3.1) [17].
При последовательном распределении вектор данных логически отделен от описания структуры хранимых данных. Например, если структура данных представляет собой линейный список (файл записей фиксированной длины), то описание структуры хранится в отдельной записи и содержит:
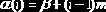
В случае линейного списка адресная функция состоит из операций смещения и масштабирования. Любые отношения, которые можно выразить на языке целых чисел, можно истолковать как отношения между элементами памяти, получая при этом всевозможные варианты структур.
В качестве примера (из [17]) рассмотрим реализацию с помощью линейного списка при последовательном распределении памяти для логической структуры типа регулярного двоичного дерева (рис. 3.2). Идея способа заключается в том, что начиная с элемента памяти ?(1), делают его корнем дерева, размещают там данные, соответствующие узлу У1. В элементах памяти ?(2) и ?(3) размещают непосредственных потомков узла У1
– узлы У2 и У3, и т.д. В общем случае, непосредственные потомки узла Ук размещаются по адресам: ?(2k) и ?(2k+1). Адресная функция имеет вид
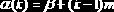
где k – номер узла древовидной структуры; р – базовый адрес; т – размер элемента памяти, который требуется для хранения данных узлов дерева (каждый узел представляет собой запись фиксированной длины). По дереву, которое при этом получается, можно двигаться в обоих направлениях, так как от узла Ун можно перейти к его потомкам, удвоив k (или удвоив k и прибавив единицу).